Jekyll2024-04-04T14:11:23+00:00https://engineering.axur.com/feed.xmlAxur Engineering blogNossa missão é tornar a internet um lugar mais seguro. Desenvolvemos tecnologia para encontrar e eliminar riscos digitais, preservando a relação de confiança entre nossos clientes e seus públicos.AxurMicrofrontends independentes através de eventos2024-02-01T03:50:00+00:002024-02-01T03:50:00+00:00https://engineering.axur.com/2024/02/01/microfrontends-independentes-atraves-de-eventosNo universo do desenvolvimento de aplicações web, enfrentamos desafios crescentes em relação à complexidade das aplicações. Especificamente no contexto de frontend, não é suficiente que uma aplicação seja visualmente agradável e intuitiva; a aplicação precisa encapsular e interpretar uma grande quantidade de conceitos de negócio, e apresentá-los a usuários de forma competente.
Esses conceitos de negócio, muitas vezes, estão interligados de formas complexas e funcionam de maneira intrincada. Por outro lado, é responsabilidade do time de desenvolvimento de software controlar a complexidade das bases de código, para que elas não se transformem em um obstáculo para o desenvolvimento ágil e eficiente. Nesse cenário, uma das missões do time de Engenharia da Axur é justamente gerenciar a complexidade das nossas bases de código mantendo a qualidade técnica do software desenvolvido.
Microfrontends independentes
Uma das respostas para lidar com a complexidade crescente é fragmentar a aplicação em pedaços menores, independentes e coesos. Chamaremos esses pedaços de microfrontends. A ideia principal é criar microfrontends como unidades independentes de funcionalidade, que interagem entre si para construir a experiência do usuário final. Dessa forma, times de desenvolvimento podem distribuir a responsabilidade e trabalhar simultaneamente em diferentes áreas de uma mesma aplicação, sem interferir uns nos outros.
Mesmo nesse cenário, é improvável que todos os casos de uso de uma aplicação possam ser atendidos por um único microfrontend. Eventualmente, pode ser necessário que dois subsistemas distintos compartilhem informações. Desse ponto, surge um novo desafio: como esses microfrontends, que atuam como ilhas de funcionalidade, comunicam-se entre si?
Imagine um componente de carrinho de compras, responsável por armazenar temporariamente todos os produtos de uma sessão do usuário. Imagine também a página de um produto específico. É natural imaginar que esses casos de uso sejam implementados em microfrontends distintos e independentes. E se, nesse cenário, o carrinho de compras precisar ser atualizado (ou exibir uma animação) quando o usuário clicar no botão de “comprar” em uma página de produto? Como o carrinho de compras pode ser informado do novo produto recém selecionado?
Emissão de eventos
Uma solução possível é estabelecer um canal de comunicação que não requer acoplamento direto entre dois microfrontends. Podemos fazer isso através de uma solução de mensageria compartilhada. Neste modelo, permitimos que microfrontends que compartilham o mesmo ambiente de execução possam trocar mensagens entre si.
Comandos: São enviados de qualquer remetente para um destinatário específico. Comandos indicam claramente a ação que deve ser realizada pelo destinatário, e são escritos usando a linguagem de domínio do destinatário. A título de exemplo, uma solicitação de mudança de rota pode ser tratada como um comando.
Eventos: Diferentemente de comandos, eventos são emitidos por um remetente específico e podem ser capturados por quaisquer destinatários interessados. Eventos indicam acontecimentos relevantes, e são escritos em termos do domínio do remetente. Isso garante que o remetente não precise conhecer detalhes de implementação dos destinatários. A título de exemplo, um evento pode ser disparado quando o resultado de uma lista é renderizado na tela ou quando um usuário realiza login com sucesso.
Consumo de eventos
O consumo de mensagens é feito por handlers, que podem ser registrados em um microfrontend para que sejam invocados sempre que determinado evento for disparado na aplicação. Cada microfrontend é responsável por declarar e inicializar os seus próprios handlers, preferencialmente em um ponto centralizado da aplicação. Isso permite que os eventos aceitos por cada microfrontend sejam facilmente identificados por um leitor externo.
Mensageria usando a DOM
A estratégia de comunicação por mensagens pode ser implementada de inúmeras formas, seja através de uma implementação própria ou com o auxílio de uma biblioteca específica. A DOM (Document Object Model) é uma API presente em todos os browsers e que fornece interfaces para o tratamento de eventos personalizados (Custom Events). Esse ferramental pode ser utilizado para criar uma solução simples de mensageria, disparando mensagens como Custom Events e registrando event handlers para tratá-los na aplicação.
A título de exemplo, o código TypeScript abaixo utiliza APIs da DOM para enviar um evento de login para a aplicação. O evento enviado contém também o ID e o nome do usuário logado:
Em outro ponto da aplicação, um microfrontend interessado no evento de login pode registrar um handler, tratando o evento conforme necessário:
constloginHandler=(event:CustomEvent)=>{constid=event.detail.user.id;constname=event.detail.user.name;alert(`User ${name} (id ${id}) just logged in!`);}document.addEventListener('event.login.success',loginHandler);
A partir desse ponto, o loginHandler será invocado sempre que um evento de tipo 'event.login.success' chegar ao objeto document. O envio de um evento de login pode ser feito chamando a função notifyLogin definida anteriormente:
notifyLogin('123','Jane Doe');
Na implementação acima, é importante notar que os dois módulos (produtor e consumidor) são completamente independentes. O acoplamento entre produtor e consumidor de eventos se dá apenas pelo contrato entre os dois módulos, que pode ser interpretado como uma API definida pelo emissor. Essa API define o tipo do evento e o formato do payload, mas não faz nenhuma suposição quanto à existência de consumidores. Da mesma forma, consumidores de eventos simplesmente respeitam o contrato definido sem fazer nenhuma suposição quanto à existência de um emissor. Essa característica garante o baixo acoplamento entre os dois módulos.
Vale notar também que essa implementação é apenas um exemplo de como atingir o baixo acoplamento, utilizando APIs amplamente disponíveis em navegadores. Como já mencionado, existem diferentes formas de implementar a comunicação através de mensagens, e até mesmo bibliotecas que disponibilizam um ferramental similar para lidar com produtores e consumidores.
Conclusão
Com a comunicação baseada em eventos, equipes de software podem desenvolver, testar e implementar novas funcionalidades de forma mais ágil. A emissão de eventos permite a criação de componentes independentes, de forma que múltiplas equipes trabalhem simultaneamente em diferentes partes da aplicação sem interferir umas nas outras. Da mesma forma, essa estratégia de comunicação promove o desacoplamento ao implementar uma nova interface entre dois subsistemas independentes. Por fim, ao evitar o acoplamento direto, erros ou falhas em um subsistema (no nosso caso, em um microfrontend) deixam de afetar diretamente o comportamento de outros, garantindo uma experiência mais estável a usuários.
Em aplicações complexas, o desacoplamento de conceitos é vital para garantir escalabilidade e flexibilidade. Nesse artigo, exploramos uma estratégia de mensageria como forma de comunicação entre microfrontends, permitindo que ilhas de funcionalidades isoladas possam se comunicar sem a necessidade de criar dependências rígidas entre elas. Adotando esse padrão, equipes de desenvolvimento podem se beneficiar de um processo de trabalho mais ágil e independente, além de uma arquitetura mais limpa e uma experiência mais robusta para o usuário final.
]]>Guilherme Rezende AllesTransformação de schemas relacionais sem downtime2021-08-10T18:00:00+00:002021-08-10T18:00:00+00:00https://engineering.axur.com/2021/08/10/schemas-relacionais-sem-downtimeComo explicamos neste artigo, uma de nossas práticas para maximizar a entrega de software é a transformação de deployments em eventos triviais, que acontecem a qualquer hora, muitas vezes por dia. Pensando nisso, não podemos aceitar que a entrega de novas funcionalidades e melhorias cause possíveis downtime, com interrupção de serviço que impacte os usuários. Nesse contexto, um problema bem específico se manifesta: como podemos aplicar mudanças nas estruturas de tabelas já existentes de bancos de dados relacionais, mantendo os microsserviços que dependem deles em funcionamento durante todo o processo? Neste artigo, vamos apresentar uma solução possível a partir de uma necessidade real: a mudança de charset de uma tabela para suportar caracteres especiais.
O jeito mais comum e simples de fazer essa mudança é usando o comando do MySQL para alterar o charset da tabela (ALTER TABLE table CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci), porém este comando impossibilita a leitura e escrita na tabela que está sofrendo alteração. No nosso cenário, a tabela contém 60 milhões de registros e foi estimado que levaria de 2 a 3 horas para concluir a execução do comando. Era inviável deixar o microsserviço parado por 3 horas e impactar todos os usuários da nossa plataforma, então decidimos seguir outra abordagem para que não houvesse downtime no microsserviço.
Nesta outra abordagem decidimos não usar o comando de alteração. Optamos por recriar a tabela, desta vez com o charset correto. Também tivemos que replicar toda a estrutura para manter a coerência entre as constraints das tabelas.
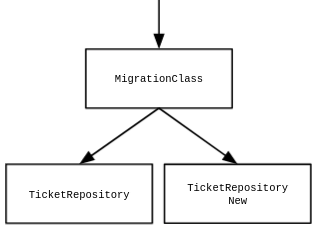
Outro ponto que tivemos que repensar foi como seria feita a migração dos dados que estavam na tabela antiga. Se simplesmente fossem migrados todos os dados antes do microsserviço apontar para a nova tabela, o problema de downtime não seria resolvido, porque teríamos que parar o microsserviço, fazer a migração e depois colocar a nova versão que aponta para a nova tabela. Com isso chegamos à solução final, na qual decidimos realizar a migração de dados adicionando uma lógica no código para acessar os dados antigos e os novos. Abaixo a organização da implementação desta solução
Portanto os novos registros eram salvos na tabela nova, e os registros na tabela antiga eram migrados à medida que os dados eram consultados. Para facilitar o entendimento, segue um snippet do código da classe (migrationClass) que contém as lógicas para inserção, consulta e atualização.
Todos os registros novos, são inseridos na tabela novas.
A consulta aos registros foi alterada. Além de ler os dados, também é realizada a migração dos registros para a tabela nova, caso eles se encontrem na tabela antiga. Depois de salvo na nova tabela, o registro é excluído da antiga.
publicTicketfind(Integerid){try{TicketticketOld=ticketRepository.find(id);migrationTicket(ticketOld)}catch(TicketNotFoundExceptione){logger.debug("Ticket not found in old table: {}",id);}returnticketRepositoryNew.find(id);}
A atualização de registros segue a lógica da consulta: caso o registro esteja na tabela antiga, primeiro ele é migrado para a tabela nova e depois sofre a atualização.
publicvoidupdate(Ticketticket){try{TicketticketOld=ticketRepository.find(ticket.id());migrationTicket(ticketOld)}catch(TicketNotFoundExceptione){logger.debug("Ticket not found in old table: {}",id);}ticketRepositoryNew.save(ticket);}
Com essa solução foi possível suportar UTF-8 na tabela, sem qualquer downtime no serviço. Os dados foram migrados aos poucos, sem sobrecarregar o sistema, uma vez que a migração só ocorre ao consultar/atualizar alguma informação. Os dados que permaneceram na tabela antiga, por não terem sido consultados/atualizados no período dedicado a migração automática, foram migrados manualmente após algum tempo, sendo finalizada a migração e possibilitando a remoção da tabela antiga e do código de migração.
]]>Matheus Rodrigues da SilvaMicro-benchmarks em Java2021-05-27T13:13:00+00:002021-05-27T13:13:00+00:00https://engineering.axur.com/2021/05/27/micro-benchmarksDurante a participação em um projeto, o engenheiro de software pode ter que passar pelo processo de escolha
de uma determinada biblioteca, framework ou componente dentre uma gama de possibilidades, baseado no
desempenho do componente. Pode ser necessário escolher qual a biblioteca de serialização de JSONs mais
rápida, qual a biblioteca de processamento de expressões regulares mais rápida, e assim por diante. Geralmente,
será possível encontrar na Internet benchmarks prontos e de qualidade para os tópicos mais quentes do mundo da
programação, contudo, para casos particulares, pode ser necessário que o próprio engenheiro tenha que executar
seus benchmarks para ajudar no processo de decisão. Neste artigo, abordaremos alguns aspectos do processo de
criação/execução de micro-benchmark em Java para o caso em que seja necessária a criação rápida de benchmarks.
O que é um micro-benchmark?
Um micro-benchmark é um benchmark rápido e leve, com o objetivo de testar rapidamente alguma ideia ou
conceito no código, podendo inclusive ser descartado após a obtenção dos resultados. Em geral, o enfoque
do micro-benchmark é a comparação entre duas ou mais opções. Isso o diferencia do profiling, que é a análise
do desempenho de um código com objetivo de otimização, incluindo possivelmente a análise de frequência e
duração das chamadas de métodos.
Um exemplo de micro-benchmark pode ser um benchmark que mostra qual componente é mais rápido em gerar
um número aleatório, comparando entre java.util.Random e java.util.SplittableRandom. É um benchmark
rápido que pode guiar as decisões de desenvolvimento de um componente mais complexo, e também é um assunto
que não é tão quente e pode não haver um benchmark pronto na Internet.
Anatomia de um micro-benchmark
O micro-benchmark mais simples é composto de um trecho de código a ser testado, e de uma rotina que chama
esse código cronometrando o tempo que o código testado leva para rodar. Contudo, os
benchmarks mais úteis são aqueles que comparam diversas abordagens de forma a auxiliar em uma tomada de
decisão. Assim, o micro-benchmark mais comum possui dois ou mais trechos de código a serem testados,
sendo um deles considerado o código padrão (chamado baseline) e as outras opções sendo variações ou opções
do mesmo código a fim de provar alguma hipótese ou conceito.
O trecho de código acima é um exemplo de micro-benchmark bem simples que serve para cronometrar o tempo
necessário para Random retornar um número inteiro aleatório de 32 bits. Contudo, o trecho de código também
é um exemplo de um micro-benchmark de baixa qualidade, e veremos o motivo a seguir.
Armadilhas em micro-benchmarks em Java
A máquina virtual Java (JVM) é muito boa em otimização de código, incluindo o uso do compilador Just-In-Time (JIT)
para geração de código de máquina a fim de acelerar os caminhos críticos de execução de código.
Além disso, a JVM também é muito boa em
esconder os detalhes de otimização de forma que os desenvolvedores não precisem se preocupar em
micro-gerenciamento dos pormenores de otimização. Contudo, esse gerenciamento de otimização pode ser
relevante para benchmarks, pois a natureza sintética do benchmark pode induzir a máquina virtual
a fazer otimizações inesperadas ou indesejáveis. A seguir, vamos enumerar algumas situações que podem gerar
um comportamento inesperado em micro-benchmarks.
Remoção de variáveis e resultados que nunca são lidos
A JVM possui uma implementação bem madura para detectar código inútil ou nunca utilizado,
e isso também vale para variáveis que são gravadas e nunca são lidas.
Nesse caso, a atribuição é um candidato a ser eliminado do caminho de execução.
Caso a atribuição tenha efeitos colaterais, por exemplo a chamada de uma rotina, o otimizador pode desmembrar
os efeitos colaterais e descartar a parte não usada pelo retorno da rotina. O código a seguir é um exemplo em
que a atribuição da variável result pode ser suprimida pois a variável nunca é lida.
Em geral, a JVM executa o bytecode Java através de interpretação do bytecode, que é um processo muito mais
lento do que a execução de código de máquina. Contudo, a JVM também possui disponível um compilador JIT para
geração de código de máquina em tempo de execução. Apesar disso, nem todo código é transformado em
código de máquina, pois a geração de código de máquina é um processo custoso e que consome recursos
computacionais importantes. Em face disso, o otimizador analisa o perfil de execução de trechos de código
e escolhe, em tempo de execução, os códigos executados com maior frequência como candidatos para execução
através do JIT. Dessa forma, o código de um micro-benchmark precisa ser executado dezenas ou centenas de
vezes a fim de garantir que o otimizador prepare o código para ser executado através de JIT. As primeiras
execuções também precisam ser descartadas, pois representam a execução do código de maneira interpretada, e
podem causar um desvio estatístico nos tempos calculados.
Remoção de gravações intermediárias para uma mesma variável
Caso uma variável seja gravada diversas vezes, o otimizador pode suprimir as diversas gravações e manter
somente a última atribuição. Caso o valor da última atribuição dependa das gravações intermediárias, por
exemplo em um laço, o otimizador ainda pode tentar algumas otimizações para suprimir o laço, incluindo
calcular o valor final a frente e manter apenas a última atribuição, eliminando completamente o laço.
Este ponto é especialmente importante no caso de micro-benchmarks executados em um laço - que é um caso
comum em vista da necessidade de aquecimento do JIT.
Granularidade da base de tempo
Às vezes, pode ser necessário fazer o benchmark de um código que executa muito rápido, por exemplo
a comparação entre o acesso a um vetor usando MethodHandle e VarHandle, cujo tempo de execução é da ordem
de nanosegundos. Para casos assim, existe a dificuldade de obter uma base de tempo precisa e da ordem de
nanosegundos, pois as bases de tempo mais comuns disponíveis para o desenvolvedor possuem uma granularidade
da ordem de alguns milissegundos. Além disso, para marcações de tempo menores do que 1 milissegundo,
existe a possibilidade de que os testes possam conter ruído das imprecisões causadas pelo próprio sistema
operacional, como trocas de contexto e interrupções de hardware.
Para contornar este problema, a saída mais comum é executar o código em teste diversas vezes, acumulando
o tempo total de execução e depois calculando o tempo médio de cada execução. Dessa forma, o ruído da
imprecisão presente em algumas execuções estará diluído entre todas as centenas ou milhares de execuções.
Execução do Garbage-Collector
O garbage-collector pode ser executado pela JVM a qualquer momento, incluindo durante a execução do
micro-benchmark, provocando pausas na execução e outros efeitos que podem causar divergências nos resultados.
A execução (ou não execução) do garbage-collector é um elemento da JVM que não é fácil de ser controlado pelo
desenvolvedor, e por isso mesmo é um ponto relevante a ser levado em conta na construção do código de teste.
A maneira mais fácil para tentar aliviar os efeitos das execuções do garbage-collector é evitar grandes
alocações de memória, bem como executar o teste centenas ou milhares de vezes a fim de distribuir o desvio
estatístico causado por ele.
Como criar um micro-benchmark de qualidade?
Conhecendo algumas das principais armadilhas para a construção de um benchmark, podemos enumerar os
principais pontos necessários para a construção de um bom código de teste:
Evitar a eliminação de código, armazenando e/ou usando os valores retornados pelos códigos em teste em
variáveis públicas e/ou voláteis. A semântica do modificador volatile do Java pode ajudar a impedir
que atribuições sejam eliminadas pelo otimizador, já que informa ao otimizador que a variável pode ser
lida/gravada a qualquer momento por outras threads.
Executar o código muitas vezes antes da execução cronometrada do teste, a fim de aquecer o JIT, de forma que
o bytecode seja transformado em código de máquina.
Executar o código muitas vezes a fim de diluir ruídos na marcação de tempo que podem ocorrer por causa de
fatores externos (sistema operacional, hardware), fatores internos (execução do garbage-collector,
execução do otimizador JIT) ou granularidade da base de tempo.
Certamente, um código de teste pode ser construído levando em consideração todos esses requisitos sem
muita dificuldade. A seguir é mostrado um código de micro-benchmark que mostra o tempo de execução médio
para uma construção do tipo variable = random.nextInt();.
publicclassSelfMadeMicroBenchmarkRandomNextInt{publicstaticvolatileintsinkHole;publicstaticvoidmain(String[]args){executeBenchmark();}privatestaticvoidexecuteBenchmark(){intmaxCount=100000000;Randomrandom=newRandom();for(intpass=0;pass<8;pass++){longstartTime=System.currentTimeMillis();for(intcount=0;count<maxCount;count++){sinkHole=random.nextInt();}longstopTime=System.currentTimeMillis();doubleaverageTime=(stopTime-startTime)*1000000.0/maxCount;System.out.printf("PASS %d: average %.2f ns%n",pass,averageTime);}}}
Ao executar o código, a saída obtida é a seguinte:
PASS 0: average 10.94 ns
PASS 1: average 12.97 ns
PASS 2: average 13.06 ns
PASS 3: average 12.97 ns
PASS 4: average 12.95 ns
PASS 5: average 12.93 ns
PASS 6: average 12.95 ns
PASS 7: average 12.93 ns
Como podemos ver acima, o primeiro passe possui um certo nível de ruído inserido, inclusive mostrando um
valor menor do que a média dos valores seguintes. De qualquer forma, o código é muito simples e não mostra
atributos estatísticos da amostragem, por exemplo o desvio padrão e erro médio, que poderiam ser dados
interessantes a serem mostrados dependendo da natureza do teste.
Usando JMH para escrever micro-benchmarks de qualidade
O Java Microbenchmark Harness (JMH) é um framework para criação rápida de micro-benchmarks em Java,
sendo que podemos destacar como principais vantagens a facilidade de escrita do teste,
e a abstração dos principais problemas de otimização ocultos pela JVM.
Para usar o JMH é bem simples, primeiramente acrescentando as seguintes dependências no arquivo POM do projeto Java:
Ao rodar o método main da classe JmhRegexExample, o componente JMH executa o benchmark para os dois
métodos marcados com @Benchmark, exibindo os resultados ao final. Para o exemplo, estamos verificando a
diferença de desempenho entre usar uma regex pré-compilada e compilar a regex a cada teste.
Quem está acostumado com JUnit deve ter notado que os métodos de benchmark não estão com retorno
do tipo void. Esta é uma das várias features do JMH, e neste caso auxilia o otimizador para que não
simplifique a execução do processamento para o valor de retorno não usado visto anteriormente na seção
“Remoção de variáveis e resultados que nunca são lidos”.
Após mais de 18 minutos de processamento do benchmark, os resultados obtidos foram os seguintes:
# Run complete. Total time: 00:18:23
Benchmark Mode Cnt Score Error Units
JmhRegexExample.notPreCompiledRegex thrpt 25 560290,156 ± 26009,161 ops/s
JmhRegexExample.preCompiledRegex thrpt 25 694972,423 ± 4512,448 ops/s
Basicamente, os resultados mostram que o uso da regex pré-compilada é quase 24% mais rápido
(score de 694.972 ops/s) do que a abordagem de compilar a regex a cada uso (score de 560.290 ops/s),
para os casos do exemplo.
Um ponto de atenção é que a configuração padrão para os testes pode demorar um tempo significativo, pois
está ajustada para executar muitas repetições. Na versão 1.31 usada no exemplo, a
configuração padrão está ajustada para executar 5 warmups e 5 iterations de 10 segundos por teste, com
5 repetições (forks) para cada teste. Para ajustar os tempos e número de repetições, podem ser usadas as
anotações @Warmup, @Measurement e @Fork, conforme os exemplos abaixo:
@Warmup(iterations = 5, time = 3000, timeUnit = TimeUnit.MILLISECONDS): antes de cada teste, o
JMH vai executar 5 warmups (campo iterations), ou seja, executar o benchmark sem
computar o tempo, de forma que o otimizador da JVM possa executar o JIT e outros componentes do fluxo de
otimização de código. Cada warmup será executado por 3000 milissegundos.
@Measurement(iterations = 5, time = 3000, timeUnit = TimeUnit.MILLISECONDS): para cada teste, o JMH
vai executar 5 iterations de 3000 milissegundos cada, registrando estatísticas para
as contagens de execução e o tempo decorrido.
@Fork(value = 2, warmups = 1): cada teste será executado 3 vezes, sendo a primeira vez a título
de warmup, ou seja, sem computar as
estatísticas, e as outras duas vezes com armazenamento das estatísticas. As repetições para o @Fork podem
envolver a execução dos testes em novas instâncias da JVM, de forma a validar a execução em uma instância
nova ao invés de reaproveitar a mesma instância para as repetições.
Dessa forma, podemos variar a estrutura de repetições dos testes para obtermos uma execução mais rápida
ou mais precisa conforme cada caso. As anotações Warmup, Measurement e Fork também podem ser usadas
a nível de classe, e então são aplicadas para todos os benchmarks dentro da classe.
O JMH também permite o ajuste do parâmetro @BenchmarkMode para selecionar o modo de cálculo do resultado
do benchmark, sendo 4 opções disponíveis: Throughput, AverageTime, SampleTime e SingleShotTime.
Caso mais de uma opção seja selecionada, o JMH vai calcular os resultados dos benchmarks dos diferentes
modos e exibir os diferentes valores ao final. Ainda é possível usar a marcação @OutputTimeUnit para informar
a unidade de tempo do resultado (TimeUnit).
Modo Throughput: o resultado será calculado em termos de contagem de operações por segundo
(ou pela unidade informada em OutputTimeUnit)
Modo AverageTime: conforme a documentação, na prática é o inverso do Throughput, ou seja, o tempo
médio para execução do método do benchmark.
Modo SingleShotTime: usado para que seja feita apenas uma execução do benchmark, sem aquecimento
e repetições.
Modo SampleTime: nesse modo, é gerada uma distribuição do tempo de execução do benchmark, mostrando
alguns percentis e seus scores, conforme o exemplo abaixo:
Cabe salientar que o trecho de código apresentado para o método main roda todos os benchmarks presentes
no projeto Java, independente de estarem localizados na mesma classe onde se encontra o método main.
Para obter um melhor controle da execução dos benchmarks, pode ser usado o OptionsBuilder conforme exemplo
abaixo, onde é selecionado para executar somente os benchmarks da classe JmhRegexExample:
Através do uso de métodos main conforme mostrado anteriormente, os benchmarks podem ser executados de dentro
do próprio IntelliJ usando os atalhos já disponíveis na interface da IDE.
Existem alguns plugins de integração à ferramenta que auxiliam o uso dela na IDE.
Um exemplo deles é o JMH Java Microbenchmark Harness,
fornecendo, dentre outras coisas, botões de atalho na IDE para a execução dos benchmarks diretamente a partir
dos métodos. Dessa forma, não há a necessidade de declaração dos métodos main, conforme o
exemplo de captura a seguir:
Conclusão
Os micro-benchmarks são uma ferramenta poderosa para auxiliar o engenheiro de software a entender melhor
os detalhes de desempenho tanto do código sendo produzido, quanto das bibliotecas e outros componentes em uso
em um projeto. Mostramos um pouco das armadilhas e detalhes escondidos em termos de otimização de código pela
JVM, que podem afetar a construção de micro-benchmarks de qualidade e gerar resultados imprecisos ou incorretos.
Mostramos também uma forma de escrever benchmarks de qualidade em Java usando o framework JMH para
construção fácil de micro-benchmarks. O JMH abstrai do desenvolvedor a maioria dos problemas e detalhes
técnicos quanto a otimização de código, fornecendo uma interface simples e concisa para a escrita dos benchmarks.
]]>Jose FerreiraOtimizando o uso de Expressões Regulares (Regex)2021-05-17T12:36:00+00:002021-05-17T12:36:00+00:00https://engineering.axur.com/2021/05/17/regex-optimizationComo descrito em nossos Pilares Técnicos, nosso objetivo como time de Engineering da Axur é construir a tecnologia que permite a nossos produtos tornarem a internet mais segura. Para tal, existem etapas essenciais para prover maior segurança na Web, como o monitoramento e a inspeção de conteúdo na internet. É dessa forma que identificamos possíveis ameaças aos nossos clientes. Este artigo aborda expressões regulares (regex, do inglês Regular Expressions), uma entre tantas ferramentas que utilizamos para o combate a riscos digitais.
De mecanismos simples como comparação de strings até recursos mais complexos como o uso de Machine Learning, existe uma variedade de tecnologias e conhecimentos técnicos aplicados para processar a enorme quantidade de dados que coletamos na internet — tudo isso em tempo hábil e com custo computacional apropriado. Entre essas tecnologias, o uso de expressões regulares destaca-se como um forte aliado para executarmos buscas flexíveis em conteúdos diversos. Todavia, o emprego inapropriado de regex gera gargalos de processamentos, principalmente em um cenário de alto throughput de dados.
Aqui, discutiremos diferentes aspectos da utilização de expressões regulares, com benchmarks, otimizações e comparativos de resultados. Não será abordada a sintaxe das expressões. Este artigo também não tem o objetivo ser um manual exaustivo de todas as otimizações possíveis, e sim, mostrar alguns pontos importantes ao se trabalhar com regex.
Compile uma única vez
Linguagens de programação geralmente possuem suporte built-in ao uso de regex. Esse uso pode ser classificado em duas etapas principais: compilação e matching.
Na compilação, a expressão é transformada em uma sequência de instruções internas que serão usadas por um motor de correspondência (regex/matching engine). Para o matching, um determinado conjunto de caracteres é comparado com esse padrão compilado para verificar equivalência. Em Python, por exemplo, o motor desenvolvido em C interpreta bytecodes gerados.
Aqui temos exemplos em diferentes linguagens de programação do uso da compilação e matching. Neste caso, o código busca a palavra "internet" na frase "a Axur torna a internet mais segura".
[...]finalPatternpattern=Pattern.compile(".*internet.*");finalMatchermatcher=pattern.matcher("a Axur torna a internet mais segura");booleanhasMatched=matcher.find();// uso do “find” para que seja procurada uma substringSystem.out.println("has matched: "+hasMatched);[...]
importrepattern=re.compile('.*internet.*')has_matched=pattern.match('a Axur torna a internet mais segura')print("has matched:",bool(has_matched))
Dependendo da linguagem de programação, existem outros meios de verificar a palavra na frase com outras sintaxes, objetos, funções, classes e métodos. Todavia, o ponto é que, devido ao custo computacional da compilação da regex, deve-se evitar a necessidade de recompilá-la toda vez que há uma verificação de matching. Para demonstrar os efeitos da compilação, veja o código a seguir:
[...]finalList<String>allRegex=generateRegexes(keywords);finalString[]contents={"a axur torna a internet mais segura","Detecte e remova fraudes digitais da internet automaticamente","Takedown proativo e transparente"};longtotalTimeInMsForMethod1=0;longtotalTimeInMsForMethod2=0;System.out.println("Processing... it may take a while...");for(inti=0;i<TOTAL_CHECKS;i++){Stringcontent=randomContentFrom(contents);for(Stringregex:allRegex){totalTimeInMsForMethod1+=alwaysCompilingMethod(regex,content);totalTimeInMsForMethod2+=cachedPatternCompilingMethod(regex,content);}}System.out.println("Average time (ms) for Method 1: "+totalTimeInMsForMethod1/TOTAL_CHECKS.floatValue());System.out.println("Total time (seconds) for Method 1: "+totalTimeInMsForMethod1/MILLIS_IN_SECONDS);System.out.println("Average time (ms) for Method 2: "+totalTimeInMsForMethod2/TOTAL_CHECKS.floatValue());System.out.println("Total time (seconds) for Method 2: "+totalTimeInMsForMethod2/MILLIS_IN_SECONDS);[...][...]privatestaticlongalwaysCompilingMethod(Stringregex,Stringcontent){longstartTime=System.currentTimeMillis();Patternpattern=Pattern.compile(regex);Matchermatcher=pattern.matcher(content);sinkHole=matcher.find();longendTime=System.currentTimeMillis();returnendTime-startTime;}privatestaticlongcachedPatternCompilingMethod(Stringregex,Stringcontent){longstartTime=System.currentTimeMillis();Matchermatcher=matcherFromCache(regex,content);sinkHole=matcher.find();longendTime=System.currentTimeMillis();returnendTime-startTime;}privatestaticMatchermatcherFromCache(Stringregex,Stringcontent){if(cachedPatterns.containsKey(regex)){returncachedPatterns.get(regex).matcher(content);}else{Patternpattern=Pattern.compile(regex);cachedPatterns.put(regex,pattern);returnpattern.matcher(content);}}[...]
Este código gera 10.000 expressões regulares combinando palavras-chave (keywords). Então, são verificados se os padrões das expressões têm correspondência com 1.000 conteúdos randômicos. A ideia deste algoritmo é simular uma ampla gama de conteúdos diferentes testados com uma grande variedade de regexes para matching.
Para o benchmark são usados dois métodos distintos: um que compila a regex em toda verificação de match da expressão com o conteúdo (método 1) e outro que compila uma única vez e salva em memória o padrão compilado para reuso (método 2). Ou seja, o segundo método usa um mecanismo simples de cache. O resultado da execução do código é o seguinte:
Average time (ms) for Method 1: 40.592
Total time (seconds) for Method 1: 40
Average time (ms) for Method 2: 24.546
Total time (seconds) for Method 2: 24
Cada execução pode gerar resultados diferentes de acordo com o ambiente utilizado. Entretanto, independentemente disso, existe diferença significativa entre os métodos. Nesse ambiente, com uso de caching, a velocidade de processamento foi 66% maior.
Fique atento! De acordo com a linguagem utilizada, este mecanismo pode estar embutido de alguma forma. Em Python, a operação de compiling usa cache em memória. O trecho a seguir foi retirado da Python Standard Library, mais especificamente do arquivo "re.py":
Código do re.py
_MAXCACHE=512def_compile(pattern,flags):# internal: compile pattern
ifisinstance(flags,RegexFlag):flags=flags.valuetry:return_cache[type(pattern),pattern,flags]exceptKeyError:passifisinstance(pattern,Pattern):ifflags:raiseValueError("cannot process flags argument with a compiled pattern")returnpatternifnotsre_compile.isstring(pattern):raiseTypeError("first argument must be string or compiled pattern")p=sre_compile.compile(pattern,flags)ifnot(flags&DEBUG):iflen(_cache)>=_MAXCACHE:# Drop the oldest item
try:del_cache[next(iter(_cache))]except(StopIteration,RuntimeError,KeyError):pass_cache[type(pattern),pattern,flags]=preturnp
É importante lembrar: há um trade-off entre velocidade de processamento e uso de memória , pois a cache irá gastar invariavelmente mais recursos de memória.
Tamanho do conteúdo e complexidade das expressões
A velocidade de processamento de matching de uma regex depende de ao menos dois fatores: complexidade da expressão e tamanho do conteúdo em que é feita a busca do padrão da expressão. Para demonstrar o impacto dessas duas variáveis, temos o seguinte benchmark.
Os resultados da execução do código foram os seguintes:
For simple regex, increasing content size....
Took 2 ms
Took 1 ms
Took 94 ms
Took 53 ms
For complex regex, increasing content size....
Took 2 ms
Took 4 ms
Took 112 ms
Took 323 ms
* os resultados variam a cada execução, mas eles mantêm sempre a notável diferença entre os tempos para as diferentes combinações de regexes e conteúdos.
Pelos resultados, há impacto significativo de ambas as variáveis. Para dois conteúdos idênticos, com uma regex mais complexa entre um conteúdo e outro, o tempo aumentou em mais de 6 vezes. Já para duas regexes idênticas o tempo cresceu em mais de 160 vezes, com o aumento do conteúdo entre uma comparação e outra.
Assim, fica clara a importância de verificar a complexidade da expressão. Ademais, é interessante identificar se o conteúdo pode ser reduzido antes da comparação. Por exemplo, se for desejado buscar algum texto em página Web pode ser que faça sentido aplicar a regex apenas no texto visível e não em todo o HTML da página.
Otimização nas expressões
Um ponto importante é entender como funcionam regexes e suas sintaxes na linguagem de programação escolhida pelo desenvolvedor. O mau uso da sintaxe pode gerar duas expressões regulares equivalentes em matching de padrões, mas com desempenhos completamente distintos. Isso pode ser facilmente verificado no benchmark abaixo:
[...]PatternnotOptimizedPattern=Pattern.compile(".?.?.?.?.?.?.?.?.?.?.?.?.?.?.?.?.?.?.?.?.?"+"(m.?e.?u.?s.?i.?t.?e.?|site|meusite|minhapagina|teste|website|internet|p[aá]gina|"+"(my).?site|sitenovo)");PatternoptimizedSamePattern=Pattern.compile(".{0,21}"+"(m.?e.?u.?s.?i.?t.?e.?|site|meusite|minhapagina|teste|website|internet|p[aá]gina|"+"(my).?site|sitenovo)");StringcontentThatDoesNotMatch="uma string com mais de vinte um caracteres no inicio fazendo que o match não ocorra";StringcontentThatMatches="uma string qualquer sitenovo";System.out.println("For NOT optimized regex...");testMatching(contentThatDoesNotMatch,notOptimizedPattern);testMatching(contentThatMatches,notOptimizedPattern);System.out.println("For optimized regex...");testMatching(contentThatDoesNotMatch,optimizedSamePattern);testMatching(contentThatMatches,optimizedSamePattern);[...]
O resultado, em tempo para processamento, é absurdamente diferente :
For NOT optimized regex...
Took 36796 ms - Result:false
Took 1 ms - Result:true
For optimized regex...
Took 1 ms - Result:false
Took 0 ms - Result:true
A otimização teve êxito: as expressões são equivalentes em matching de conteúdos e o tempo de processamento foi reduzido drasticamente em um dos casos. Com apenas a substituição das sequências de .? pelo uso de quantificadores {n,m}, notou-se aumento na velocidade de processamento em dezenas de milhares de vezes.
Por que isso ocorre? Java utiliza autômatos finitos não determinísticos — como pode ser visto aqui — para resolver as expressões. O algoritmo usa o mecanismo de backtracking, testa todas as expansões da expressão regular e aceita a primeira correspondência encontrada. Por conta das sequências de .?, existe uma explosão de caminhos que devem ser verificados, prejudicando o desempenho.
Em outras implementações algorítmicas esses resultados podem ser bem diferentes. Por este motivo, é importante conhecer a implementação utilizada e realizar validações nas regexes criadas. Para o uso da regex padrão do Java, o impacto da não otimização da regex é enorme e pode gerar gargalos significativos em um sistema. No código equivalente em Python também há diferença nos tempos de processamento entre as expressões, porém o tempo total de execução da aplicação foi muito menor que em Java. Isso não é um problema da linguagem, apenas que neste cenário , o matching engine do Java foi menos eficiente que o motor usado por Python.
[...]not_optimized=re.compile(".?.?.?.?.?.?.?.?.?.?.?.?.?.?.?.?.?.?.?.?.?"+"(m.?e.?u.?s.?i.?t.?e.?|site|meusite|minhapagina|teste|website|internet|p[aá]gina|"+"(my).?site|sitenovo)")optimized=re.compile(".{0,21}(m.?e.?u.?s.?i.?t.?e.?|site|meusite|minhapagina|teste|website|internet|p[aá]gina|"+"(my).?site|sitenovo)")content_that_does_not_match="uma string com mais de vinte um caracteres no inicio fazendo que o match não ocorra"content_that_matches="uma string qualquer sitenovo"print("For NOT optimized regex...")test_matching(content_that_does_not_match,not_optimized)test_matching(content_that_matches,not_optimized)print("For optimized regex...")test_matching(content_that_does_not_match,optimized)test_matching(content_that_matches,optimized)[...]
For NOT optimized regex...
Took 503.0701160430908 ms - Result: False
Took 0.0059604644775390625 ms - Result: True
For optimized regex...
Took 0.004291534423828125 ms - Result: False
Took 0.0016689300537109375 ms - Result: True
Só use se necessário
Sempre verifique se a utilização da expressão regular faz sentido em determinado contexto. Muitas vezes podemos substituí-la por outros recursos da linguagem que melhoram o desempenho do código e o tornam mais legível. Vejamos o exemplo a seguir:
[...]finalString[]names={"João da Silva","Eduardo dos Santos","Maria Joana","Carlos de Jesus"};Patternregex=Pattern.compile("^João .*");System.out.println("With regex...");for(Stringname:names){checkFirstNameWithRegex(name,regex);}System.out.println("Without regex...");for(Stringname:names){checkFirstNameWithStartsWith(name);}[...][...]privatestaticvoidcheckFirstNameWithStartsWith(Stringname){longstartTime=System.nanoTime();booleanhasMatched=name.startsWith("João ");System.out.println("Took "+(System.nanoTime()-startTime)+" ms - Matched: "+hasMatched);}privatestaticvoidcheckFirstNameWithRegex(Stringname,Patternregex){longstartTime=System.nanoTime();booleanhasMatched=regex.matcher(name).matches();System.out.println("Took "+(System.nanoTime()-startTime)+" ms - Matched: "+hasMatched);}[...]
Neste código, procura-se o primeiro nome "João" em uma lista de nomes. O resultado apresenta variações de desempenho entre os conteúdos. Houve melhor desempenho no uso do método startsWith em vez de regex no teste realizado.
With regex...
Took 410914 ns - Matched: true
Took 13858 ns - Matched: false
Took 7386 ns - Matched: false
Took 6795 ns - Matched: false
Without regex...
Took 10815 ns - Matched: true
Took 2538 ns - Matched: false
Took 1745 ns - Matched: false
Took 1529 ns - Matched: false
A performance pode ser irrelevante para um cenário simples como esse. Entretanto, o método startsWith também deixa mais clara a intenção do código que a expressão regular. Isso deve ser considerado na solução, afinal, um código é muito mais lido que escrito.
Conclusão
Neste artigo mostramos testes que comprovam o impacto da compilação e sintaxe das expressões. Também ficam claros os efeitos das otimizações realizadas e a diferença entre abordagens com e sem regex. Demonstramos aqui a importância de testar e validar diferentes expressões, entender o contexto de aplicação da ferramenta e como algumas otimizações ajudam na construção de programas melhores. Em sistemas que processam grandes volumes de dados, esses cuidados podem fazer a diferença para garantir um bom desempenho e evitar gargalos.
]]>Eduardo Stein BritoGerenciamento de Memória no Java - Containers Docker2020-12-28T16:41:00+00:002020-12-28T16:41:00+00:00https://engineering.axur.com/2020/12/28/gerenciamento-memoria-java-part2Nesta segunda parte do artigo sobre Gerenciamento de Memória no Java, veremos alguns aspectos mais específicos do
Gerenciamento de Memória do Java quando estiver rodando dentro de containers Docker, bem como algumas abordagens
para configuração de memória, e também dicas de como tratar os problemas de memória mais comuns.
Para acessar a primeira parte do artigo, utilize o link abaixo:
Memória de um Processo Java/JVM dentro de um container Docker
Vimos que a JVM usa a memória total do sistema para calcular alguns parâmetros e limites, incluindo o limite de uso
do grupo Heap. Na medida em que o uso de containers Docker para rodar serviços Java se popularizou, essa
abordagem de usar o valor do total de memória do sistema para calcular alguns parâmetros se mostrou problemática.
Isso aconteceu porque os limites de memória e recursos impostos pelo Docker são direcionados para impor limites
nas chamadas do sistema, sem afetar as rotinas que fornecem informações sobre o hardware do sistema, como memória
total do computador.
Essa mudança exigiu uma abordagem ativa dos processos para que fossem compatíveis com Docker, ou seja, é esperado
que o processo detecte se está rodando dentro de um container Docker limitado, e faça o tratamento necessário
dos limites impostos pelo container.
A funcionalidade de detecção e suporte ao Docker foi adicionada ao Java na versão 8 release 181. Antes desta
versão, a JVM rodando dentro de um container Docker não era capaz de entender os limites impostos pelo Docker,
considerando a memória total do sistema e outros parâmetros sem levar em conta os limites configurados. Então,
por exemplo, considerando um computador com 4Gb de RAM rodando Docker, com uma instância Java rodando em um
container Docker com limite de memória de 512Mb e com uma versão sem suporte a Docker (anterior a versão Java 8
release 181), o limite de Heap seria ajustado para 1Gb de RAM (1/4 da memória total, que é 4Gb), e quando o
consumo de memória do processo Java ultrapassasse 512Mb o processo seria finalizado pelo serviço Docker, com o
código de erro padrão de retorno 137 para indicar que o processo ultrapassou os limites definidos pelo container.
Cabe salientar que a finalização do container através deste processo não envia sinais nem Exceções ao processo
Java, e dessa forma nenhuma Exception é executada a nível do código Java, que é simplesmente finalizado sem mais
informações.
Contudo, para as versões de JVM compatíveis com Docker (Java versão 8 release 181 e posteriores), o limite de
Heap é ajustado corretamente conforme esperado, acompanhando a configuração de limite de memória imposta pelo
container Docker. Abaixo podemos acompanhar um exemplo da variação do limite de Heap conforme o limite de memória
do container:
Memória do Docker (parâmetro -m)
MaxHeapSize
Diferença
128Mb
64Mb
64Mb
192Mb
96Mb
96Mb
256Mb
126Mb
130Mb
384Mb
126Mb
258Mb
512Mb
128Mb
384Mb
768Mb
192Mb
576Mb
1024Mb
256Mb
768Mb
Nota: dados extraídos usando a imagem openjdk:8u275-jre-slim
No gráfico acima também podemos acompanhar a diferença entre o total de memória do container e o limite de Heap,
que na prática será o espaço de memória onde será alocado o Metaspace e seus componentes, bem como o Stack, e
demais módulos específicos de cada JVM. Podemos derivar as seguintes conclusões a partir do gráfico:
O valor do limite do Heap pode ser usado para configurar a quantidade de memória alocada para o Heap e para
o Metaspace dentro do container.
A partir de um container com 256Mb, a configuração automática do limite do Heap vai alocar cada vez mais
memória para o Metaspace e pouco para o Heap, e isso pode resultar em um desperdício de memória que poderia
ser alocada para o Heap e estaria disponível dentro do Java para armazenamento de variáveis e objetos.
Em vista de tudo isso, a conclusão mais forte de todas é: quase nunca a configuração automática de Heap de um
processo Java dentro de um container Docker será a melhor configuração possível de alocação de memória. As
configurações automáticas, em geral, vão variar entre alguma das seguintes situações:
Desperdício de memória que não está alocada para o Heap e não está em uso pelo Metaspace.
Memória insuficiente alocada para o Heap, causando Exception de OutOfMemoryError durante a execução.
Memória insuficiente alocada para o Metaspace/Stack, causando finalização abrupta do container por erro
137 (limite excedido) do Docker.
Como Configurar a Memória do Java em um Container Docker?
A maneira mais simples de configurar os parâmetros de memória de um processo Java rodando em containers Docker
é através do monitoramento do consumo de memória do processo durante um teste de carga que exercite o processo
com os principais casos de uso do componente, usando, por exemplo, uma ferramenta de Profiling como o
VisualVM (open source) ou o
JProfiler (comercial). Através da ferramenta,
é possível acompanhar a variação dos valores alocado/máximo para o Heap e também para o Metaspace do processo,
obtendo um footprint do consumo de memória que pode ser usado para ajustar o limite de Heap e por consequência
o espaço disponível para o Metaspace.
Contudo, nem sempre é possível ou está disponível um teste de carga para que seja feito o Profiling do processo
Java, e nestes casos, algumas heurísticas simples podem ser usadas de forma a se obter valores iniciais para a
configuração de memória.
Uma das abordagens heurísticas mais simples para definição da memória de um processo Java rodando dentro de um
container Docker envolve a simplificação dos espaços de memória do processo em dois grupos, Heap e Metaspace
(considerando o Metaspace como contendo também o Stack), calculando um valor aproximado do consumo de Metaspace,
e ajustando o valor do limite do Heap de forma a dividir os espaços conforme o cálculo aproximado. A seguir
temos o resumo da abordagem:
Calcular um valor aproximado do consumo de Metaspace, como sendo entre 3 a 4 vezes o tamanho do conteúdo do
pacote Jar (deve ser um fat jar - um
pacote Jar contendo a aplicação e também todas as suas dependências). Como o pacote Jar é um arquivo comprimido
do tipo ZIP, deve ser consultado o tamanho do conteúdo descomprimido, ou então pode ser feita uma simplificação e
considerado entre 6 a 8 vezes o tamanho do arquivo do pacote Jar. Cabe ressaltar que a melhor abordagem é
consultar o tamanho do conteúdo, posto que existem processos de criação de pacotes Jar que não aplicam
compressão ZIP, e nesse caso pode tornar os valores muito imprecisos.
Calcular o limite do Heap como sendo a diferença entre a memória total do container e o tamanho do Metaspace
calculado acima.
Ajustar o limite do Heap no processo Java dentro do container usando o parâmetro -Xmx
Esta abordagem é boa para processos que não lançam muitas threads ou que têm um limite no número total de
threads em uso, já que o valor do Stack não é levado em conta nos cálculos.
Processos que usam muitas threads, ou que possuem ThreadPools muito grandes ou sem limites, ou listeners de
API HTTP sem limite de requisições paralelas, podem sofrer interrupções do container Docker por erro 137 na
presença de muitas threads em execução, por exemplo em situações de picos de conexões de requisições HTTP.
Para os casos em que o processo Java usa muitas threads ou pode ter picos de consumo de threads, a abordagem
heurística recomendada pode ser levemente alterada para levar em conta o consumo do Stack, conforme segue:
Calcular um valor aproximado do consumo de Metaspace, conforme a abordagem anterior.
Calcular um consumo aproximado de Stack, considerando um valor entre 512Kb e 1Mb para cada thread paralela
que se deseja que possa estar executando ao mesmo tempo. Considerando um listener de requisições HTTP em que se
deseja que até 128 requisições possam ser atendidas em paralelo, o valor de memória considerado para o Stack
seria entre 64Mb e 128Mb. Cabe salientar que, se o ThreadPool do listener HTTP não tiver limite de threads,
um pico de requisições poderá ultrapassar o número previsto e resultar na interrupção do container por erro 137.
Calcular o limite do Heap como sendo a diferença entre a memória total do container e a soma do tamanho
do Metaspace e do Stack.
Ajustar o limite do Heap no processo Java dentro do container usando o parâmetro -Xmx
Esta abordagem é boa para processos que podem lançar muitas threads, de forma a levar em conta a quantidade
de threads no cálculo dos limites de memória.
Seguindo as abordagens heurísticas descritas acima, será possível obter valores iniciais razoavelmente interessantes
para a configuração de memória de um processo Java dentro de container Docker. Ainda assim, o processo Java poderá
sofrer Exceptions e interrupções por falta de memória, e seguindo as abordagens descritas, podemos enumerar as
ações recomendadas a serem tomadas:
Caso uma thread receba uma Exception do tipo OutOfMemoryError: este caso indica que o processo Java tentou
manipular objetos muito grandes ou uma quantidade grande de objetos, associados a um limite de Heap insuficiente,
e neste caso a ação corretiva deve ser recalcular os valores de forma a fornecer mais memória Heap através do
parâmetro -Xmx. Talvez seja necessário alterar também o limite de memória total do container, já que alterar
somente o limite do Heap vai interferir com o valor alocado para o Metaspace vs Heap.
Caso o processo seja interrompido por um erro 137 do Docker: este caso indica que a área de Metaspace/Stack
do processo Java cresceu além do tamanho pré-estabelecido, por exemplo durante um pico de uso de threads ou
outra situação de uso excessivo de Metaspace. Neste caso, a ação corretiva é refazer os cálculos para aumentar
a área de memória alocada para o Metaspace. Talvez seja necessário alterar também o limite de memória total
do container, já que alterar somente o limite do Heap vai interferir com o valor alocado para
o Metaspace vs Heap.
Pontos de Atenção sobre o Consumo de Memória no Java
No Java 8 e anteriores, um String ocupa o dobro do espaço em bytes, já que é armazenado no formato UTF-16
(dois bytes por caractere). No Java 9 e posteriores, o String é armazenado como UTF-8 (1 byte por caractere)
caso não contenha caracteres especiais (acentos, emoji, etc), e o mesmo do Java 8 caso contrário.
Os processos de serialização/deserialização podem exigir até várias vezes a quantidade de memória da instância
em questão, já que várias conversões de dados devem ser feitas, como por exemplo na cadeia de conversão
entre buffer de rede do SO / buffer de memória nativa no Java (Metaspace) / vetor de bytes (Heap)
/ String (Heap) / Objeto desserializado (Heap). Isso significa, por exemplo, que um processo Java com
limite de Heap de 128Mb não é capaz de desserializar com sucesso um payload de rede de 64Mb no exemplo acima.
O stack de uma thread nunca usada em um ThreadPool praticamente não utiliza memória, já que as páginas
virtuais ainda não foram alocadas para o Stack. Contudo, uma thread já usada e que retorna para o ThreadPool
segue ocupando o Stack até que seja finalizada. Esta condição pode ser relevante em casos em que
um ThreadPool com muitas threads pode ter todas elas ocupando muito espaço de Stack, mesmo que não haja
um pico de threads, mas na condição em que todas tiverem sido utilizadas pelo menos uma vez.
]]>Jose FerreiraGerenciamento de Memória no Java2020-12-17T13:40:00+00:002020-12-17T13:40:00+00:00https://engineering.axur.com/2020/12/17/gerenciamento-memoria-java-part1O gerenciamento automático de memória do Java pode esconder do engenheiro alguns detalhes que podem ser relevantes em
certos casos de uso, como no desenvolvimento de Microsserviços e também de aplicações Serverless. Abordaremos neste
artigo alguns aspectos do gerenciamento de memória do Java que podem ser relevantes para o desenvolvimento de serviços
e aplicações headless. Para o desenvolvimento de aplicações interativas com UI, outras abordagens podem ser
necessárias/relevantes.
Este artigo está divido em duas partes. Nesta primeira parte, veremos alguns aspectos mais gerais do
Gerenciamento de Memória do Java. Na segunda parte, a ser publicada nas próximas semanas, abordaremos aspectos
sobre o Gerenciamento de Memória do Java rodando em containers Docker.
Para acessar a segunda parte do artigo, utilize o link abaixo:
Tomaremos como base a plataforma Linux, que apesar de semelhante em muitos aspectos ao Windows, é uma das plataformas
mais fáceis para deploy de aplicações não-interativas. No Linux, a memória de um processo pode ser dividida em 3
grandes classes:
Data: dados manipulados pelo processo
Text ou code: memória onde o código de máquina/executável do programa é armazenado
Stack: memória reservada para uso do stack do programa
Olhando do ponto de vista de um programa clássico em C, teremos o seguinte mapeamento:
Tipo de dados C
Local no processo
Stack, chamadas entre funções (por thread)
Stack
Inicialização de variáveis/estruturas
Data
Variáveis globais - Heap
Data
Variáveis locais - Stack
Stack
Memória dinâmica - malloc
Data
Constantes
Geralmente Data, às vezes Text
Código executável
Text
O total de memória consumido por um processo pode ser aproximado de maneira prática para a soma da memória utilizada
pelas 3 grandes classes, ou então pela soma da memória utilizada pelos tipos de dados se o processo for analisado sob
a ótica de um programa clássico C.
Memória de um Processo Java/JVM
Apesar de todos os níveis de abstração e gerenciamentos automáticos, o gerenciamento de memória de um programa Java
também pode ser avaliado sob a ótica do gerenciamento de memória de um programa C. Inclusive as principais Máquinas
Virtuais Java são escritas em C++, incluindo partes em assembler e outras linguagens.
Dessa forma, a memória de um processo Java pode ser separada nos seguintes grandes grupos:
Recurso da JVM
Grupo de memória JVM
Local no processo
Variáveis - Heap
Heap
Data
Byte code das classes
Metaspace
Data
Código executável JIT
Metaspace
Seção especial executável
Código executável da JVM
Metaspace
Text
Dados da JVM
Metaspace
Data
Memória nativa/dinâmica
Metaspace
Data
Stack (por thread)
Stack
Stack
Dependendo da implementação da JVM, este mapeamento pode ser alterado de forma a obter diferentes níveis de
desempenho/flexibilidade durante a execução. Seguiremos com a análise considerando um mapeamento como o exposto acima,
e eventuais diferenças podem ser ajustadas seguindo a abordagem apresentada.
Por padrão, a JVM clássica ajusta um limite inicial de 1/4 da memória total do sistema para o grupo Heap do processo
Java, deixando livre o tamanho dos outros grupos (na verdade, os outros grupos também possuem limites iniciais, mas
estes são ajustados com muita folga, então podem ser considerados sem limites para todos os efeitos práticos).
O valor de limite de 1/4 para o grupo Heap também pode variar, dependendo da quantidade de memória do sistema:
para valores de memória do sistema abaixo de 512Mb de RAM, o limite do grupo Heap é ajustado entre 1/4 (512Mb) e
1/2 (128Mb) do total, em vez de fixo em 1/4.
Dessa forma, ao executar um processo Java em um computador com 8Gb de RAM, a JVM vai ajustar um limite no grupo
Heap de 2Gb de RAM. Se o programa Java tentar alocar um conjunto de variáveis maior do que 2Gb de RAM, será
disparada uma Exception do tipo java.lang.OutOfMemoryError no contexto da thread que está tentando ultrapassar o
limite de alocação de memória. Cabe salientar que, antes de disparar a Exception, a JVM ainda tem uma chance de
tentar liberar memória que não está mais em uso, através da execução do
Garbage Collector.
Para controlar explicitamente o limite de memória do grupo Heap, pode ser usado o parâmetro -Xmx da JVM:
Parâmetro
Resultado
-Xmx1G-Xmx1g
Ajusta o limite do grupo Heap para 1Gb de RAM
-Xmx256M-Xmx256m
Ajusta o limite do grupo Heap para 256Mb de RAM
-Xmx256
Ajusta o limite para 256 bytes - provavelmente um erro!
java -Xmx512M -jar programa.jar
Executa o programa.jar com o grupo Heap limitado a 512Mb de RAM
Para verificar o limite do grupo Heap (e outros parâmetros de configuração da JVM) pode ser usado o comando a seguir:
Um processo Java está em execução com limite do grupo Heap de 1000Mb de RAM.
No Heap do processo existem 800Mb alocados em dados de variáveis, sendo que 500Mb dessas variáveis já não
estão mais em uso (por exemplo, o método já retornou, ou não existem mais referências para elas).
Uma thread tenta alocar um vetor de 600Mb. Neste momento, o processo precisa aumentar o tamanho do Heap para
1400Mb, sendo 800Mb (tamanho atual) + 600Mb (nova alocação). A alocação falha porque o tamanho ultrapassa o limite
de 1000Mb.
Em resposta a falha de alocação, o gerenciador de memória do Java executa o Garbage Collector.
O Garbage Collector analisa as referências das variáveis alocadas, e detecta que 500Mb dessas variáveis já não
estão mais em uso, e então libera a memória alocada por estas variáveis.
O Heap do processo, com tamanho alocado de 800Mb, agora possui 500Mb de espaço livre, e neste momento pode
atender com sucesso a requisição da thread para alocar um vetor de 600Mb, através do aumento do tamanho
do Heap para 900Mb.
Exemplo 2
Um processo Java está em execução com limite do grupo Heap de 1000Mb de RAM.
No Heap do processo existem 800Mb alocados em dados de variáveis, sendo que 100Mb dessas variáveis já não estão
mais em uso (por exemplo, o método já retornou, ou não existem mais referências para elas).
Uma thread tenta alocar um vetor de 600Mb. Neste momento, o processo precisa aumentar o tamanho do Heap
para 1400Mb, sendo 800Mb (tamanho atual) + 600Mb (nova alocação).
A alocação falha porque o tamanho ultrapassa o limite de 1000Mb.
Em resposta a falha de alocação, o gerenciador de memória do Java executa o Garbage Collector.
O Garbage Collector analisa as referências das variáveis alocadas, e detecta que 100Mb dessas variáveis já não
estão mais em uso, e então libera a memória alocada por estas variáveis.
O Heap do processo, com tamanho alocado de 800Mb, agora possui 100Mb de espaço livre, e neste momento ainda
não é possível atender com sucesso a requisição da thread para alocar um vetor de 600Mb.
Como ainda não é possível atender a requisição de alocação de memória, a requisição é considerada como uma falha
de alocação de memória.
A JVM dispara a Exception do tipo OutOfMemoryError no contexto da thread que está tentando alocar a memória
sem sucesso. Caso seja a única thread do processo e a Exception não seja tratada, o processo é encerrado com a
mensagem de erro de falta de memória.
O uso do Heap em um processo Java é o principal recurso sob controle do desenvolvedor, mas a memória alocada
pelos outros recursos também pode variar ou ser controlada direta/indiretamente através de algumas das seguintes
atividades:
Byte code das classes: o espaço alocado é proporcional ao tamanho e quantidade de classes usada pelo projeto,
e pode expandir durante a geração dinâmica de código, por exemplo, via atividade de
Aspect-oriented Programming.
Código executável JIT: depende muito da abordagem de cada tipo de JVM, mas é uma área que não varia muito em
tamanho durante a execução do processo.
Código executável da JVM: código executável fixo que compõe a parte executável da própria JVM, juntamente com
o código das bibliotecas do sistema operacional usadas, e em geral não varia durante a execução.
Dados da JVM: dados internos/de controle da própria JVM, não variam muito durante a execução.
Memória nativa/dinâmica: memória que pode ser alocada por chamadas nativas, e/ou usada por bibliotecas e outros
componentes nativos, além de buffers para IO. Pode variar bastante dependendo da interação entre o processo
e o sistema operacional, por exemplo, no acesso à rede e ao disco.
Stack: o espaço alocado é proporcional à quantidade de threads criadas/em uso pelo processo, incluindo
threads pré-alocadas em ThreadPools. A profundidade de chamadas também afeta negativamente o uso de memória.
Metaspace em um processo Java
O conceito de Metaspace foi criado a partir da versão 8 do Java, e substituiu o conceito de PermGen,
que era uma área reservada para dados permanentemente alocados da JVM (em contraste ao Heap).
Em geral, a documentação das JVMs não deixa claro o exato tamanho e composição do Metaspace e quais componentes
de fato são alocados dentro deste espaço de memória. Uma simplificação comumente usada para um processo Java é
de que o espaço alocado pelo Metaspace é a diferença entre a memória total ocupada e o valor alocado pelo Heap.
Essa simplificação nem sempre é correta, ainda mais se levarmos em conta o espaço ocupado pelo Stack, que
supostamente não faz parte do Metaspace. Contudo, essa simplificação ajuda a obter uma visão panorâmica geral
do uso de memória de um processo Java, bem próxima do uso real, e ainda ajuda a simplificar a complexidade das
diversas áreas especiais de memória do processo.
Assim como o Heap, o Metaspace também pode ser limitado através do parâmetro -XX:MaxMetaspaceSize da JVM
clássica. Contudo, diferentemente do Heap, que está diretamente sob controle do desenvolvedor e do código em
execução, a natureza da memória alocada pelo Metaspace, em geral, não pode ser determinada facilmente sem o uso
de Profiling de Memória ou outras ferramentas de instrumentação que ajudem a mostrar os valores médios de
memória em uso pelo Metaspace durante o processo em teste de carga, e por isso mesmo a configuração padrão
do parâmetro é “sem limite”.
Mesmo assim, uma das principais características do Metaspace é que seu tamanho cresce até determinado ponto
em que todos os módulos envolvidos foram ativados e usados algumas vezes, e depois seu valor estabiliza em certo
patamar que, normalmente, não é ultrapassado, a menos que haja um leak de uso de algum componente presente no
Metaspace (por exemplo a criação dinâmica de código/classes).
Próximos Passos
Na parte 2 deste artigo, veremos alguns detalhes do comportamento do gerenciamento de memória de um processo Java
rodando dentro de containers Docker, bem como algumas abordagens para configuração de memória, e também dicas
de como tratar os problemas de memória mais comuns.
Para acessar a segunda parte do artigo, utilize o link abaixo:
]]>Jose FerreiraPilares técnicos da engenharia de software na Axur2020-07-08T03:00:00+00:002020-07-08T03:00:00+00:00https://engineering.axur.com/2020/07/08/pilares-tecnicosNa Axur, o time de Engineering tem a missão de construir a tecnologia de monitoramento e reação contra riscos digitais que nos posiciona na liderança do mercado brasileiro e nos permite tornar a internet um lugar mais seguro. O desafio imposto por um ambiente online propício a ameaças e fraudes em constante evolução exige uma grande capacidade de entrega de software.
Além de colaborar na busca de soluções inovadoras, precisamos garantir que elas possam ser transformadas em código e integradas aos nossos produtos com rapidez e segurança. Mas não ficamos satisfeitos com qualquer código, que apenas funcione: além de “funcionar”, cumprindo requisitos de produto, o nosso código deve também atender às demandas dos próprios times de desenvolvimento e ajudá-los a atingir uma alta produtividade de forma constante.
Sem perder o foco no presente, pensamos também in the long run (que, aliás, é um de nossos valores culturais). Queremos estar prontos para os desafios do futuro. Poderemos comportar 10 vezes mais desenvolvedores, sem causar gargalos no trabalho de cada um e sem perder o controle sobre os riscos? Poderemos processar 1000 vezes mais informação do que processamos hoje, sem levar a uma explosão desproporcional de custos com infraestrutura?
Para que pudéssemos responder “sim” a essas e outras questões, construímos as fundações da nossa tecnologia sobre três pilares sólidos: entrega contínua, microsserviços autônomos e infraestrutura como código. Além de conjuntamente sustentarem as qualidades que almejamos (como segurança, escalabilidade, rapidez de entrega e outras), cada um desses pilares dá suporte também aos outros dois, gerando uma correlação virtuosa.
Entrega contínua
Entrega contínua (continuous delivery) é a prática de desenvolver software em pequenos incrementos de funcionalidade, mantendo-o sempre pronto a ser disponibilizado aos usuários finais com as mudanças mais recentes.
Além de times de desenvolvimento disciplinados na prática de integração contínua, o nível de entrega contínua requer também a automação completa do processo de entrega do software. O deployment pipeline - que é a manifestação automatizada desse processo - surge para guiar cada mudança aplicada ao código (commit) por uma série de etapas que incluem compilação e geração de artefatos executáveis, testes e inspeções, validações em ambientes internos e finalmente a instalação em ambiente de produção.
Como benefício mais tangível, o tempo entre o commit e o deployment em produção é reduzido drasticamente, de semanas (ou em alguns casos mais graves até meses) para poucas horas ou minutos. Deployments deixam de ser eventos críticos, carregados de tensão e riscos e agendados com antecedência, e passam a ser corriqueiros. Na Axur, fazemos dezenas de deployments por dia com todo tipo de melhorias, de funcionalidades de interface a novas fontes de detecção de ameaças.
Microsserviços autônomos
Arquiteturas de microsserviços recebem bastante atenção há alguns anos. Apesar do hype inicial, que em alguns casos levou à sua aplicação irrefletida a problemas que comportariam soluções mais simples e diretas, seus benefícios em cenários adequados puderam emergir e se consolidar. A transição arquitetural da Axur para microsserviços teve início no final de 2016 e progrediu gradualmente, com a aplicação do padrão de estrangulamento do sistema legado. Ao entrarmos no segundo semestre de 2020 estamos concluindo as últimas etapas desse processo.
Temos opiniões formadas sobre o que queremos da nossa rede de microsserviços, baseadas em aprendizados e conhecimentos prévios do domínio dos nossos problemas. Queremos unidades verdadeiramente autônomas, desde deployment e recursos de infraestrutura até a capacidade de atender a requisições sem depender de integrações síncronas com outros microsserviços. Para isso, baseamos nossa arquitetura na propagação de eventos assíncronos entre contextos, permitindo a cada um formar sua visão interna, local, do estado relevante do sistema. A visão global, portanto, passa a ser eventualmente consistente.
As vantagens dessa abordagem se estendem por todos os estágios do desenvolvimento, da concepção de novos componentes até seu monitoramento contínuo. Torna-se possível fazer grande progresso com ciclos curtos de feedback, em ambientes de desenvolvimento individuais. Já em execução, a propagação de eventos pode ser facilmente rastreada pelo sistema, e requisições externas são sempre atendidas por um único serviço - permitindo a rápida identificação de causas de falhas.
Infraestrutura como código
Como microsserviços, infraestrutura na nuvem há tempos já não é uma novidade. No entanto, são comuns os casos de aproveitamento apenas parcial do que a nuvem, e mais especificamente a infraestrutura como serviço, tem de bom para oferecer. No nosso caso, uma capacidade fundamental é usar código para eliminar a necessidade de ferramentas interativas de provisionamento. Todos gostamos de código, então por que faríamos de outra forma?
Como seria esperado, o código responsável pelo gerenciamento de infraestrutura é muito diferente do código de aplicação. Trabalhamos com templates declarativos, que especificam cada recurso necessário em todos os seus detalhes. Bases de dados (relacionais ou não), caches, armazenamento elástico de arquivos - tudo pode ser declarado em código, versionado, testado e reproduzido com confiança em diferentes ambientes.
Unindo as partes
A arquitetura de microsserviços autônomos beneficia e também é beneficiada pela prática de entrega contínua: por um lado, é impraticável controlar o deployment de dezenas ou centenas de componentes se o processo não for 100% automatizado; no caminho inverso, cada deployment pipeline é simplificado pela limitação de suas atribuições a um contexto isolado e bem definido.
Já a infraestrutura como código é uma necessidade imposta pelos dois primeiros pilares técnicos. Sem a automação do provisionamento de recursos de infraestrutura não seria possível adicionar essa importante responsabilidade ao deployment pipeline, efetivamente impedindo sua aplicação a um grande número de componentes independentes. Cada microsserviço ganha em autonomia por incluir, dentro de seu repositório de código, também seus templates de declaração de dependências de infraestrutura; e, da mesma forma que acontece com o deployment pipeline, cada template ganha em simplicidade por conter apenas o que é preciso para um único microsserviço.
Como um todo, a base técnica fornecida por esses três pilares tem mostrado solidez suficiente para suportar nossas demandas crescentes, mantendo a flexibilidade necessária para comportar e até incentivar mudanças significativas. Durante um período em que o time de Engineering foi expandido e descentralizado (de 6 para 28 colaboradores), conseguimos transformar tanto as práticas de entrega (de deployments agendados com intervalos de 6 a 8 semanas passamos a cerca de 20 deployments por dia) como a organização do próprio sistema (de três grandes componentes executáveis para uma constelação de mais de 100 microsserviços). Além das vantagens evidentes para a Axur e nossos clientes pela maior capacidade e rapidez de ação, a satisfação dos times de desenvolvimento também aumenta com a percepção de progresso contínuo.
Em artigos seguintes, abordaremos em maior profundidade cada um dos temas, com aprendizados acumulados pela Axur durante alguns anos e opções de tecnologias que podem facilitar sua implementação.