Transformação de schemas relacionais sem downtime
Como explicamos neste artigo, uma de nossas práticas para maximizar a entrega de software é a transformação de deployments em eventos triviais, que acontecem a qualquer hora, muitas vezes por dia. Pensando nisso, não podemos aceitar que a entrega de novas funcionalidades e melhorias cause possíveis downtime, com interrupção de serviço que impacte os usuários. Nesse contexto, um problema bem específico se manifesta: como podemos aplicar mudanças nas estruturas de tabelas já existentes de bancos de dados relacionais, mantendo os microsserviços que dependem deles em funcionamento durante todo o processo? Neste artigo, vamos apresentar uma solução possível a partir de uma necessidade real: a mudança de charset de uma tabela para suportar caracteres especiais.
O jeito mais comum e simples de fazer essa mudança é usando o comando do MySQL para alterar o charset da tabela (ALTER TABLE table CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci), porém este comando impossibilita a leitura e escrita na tabela que está sofrendo alteração. No nosso cenário, a tabela contém 60 milhões de registros e foi estimado que levaria de 2 a 3 horas para concluir a execução do comando. Era inviável deixar o microsserviço parado por 3 horas e impactar todos os usuários da nossa plataforma, então decidimos seguir outra abordagem para que não houvesse downtime no microsserviço.
Nesta outra abordagem decidimos não usar o comando de alteração. Optamos por recriar a tabela, desta vez com o charset correto. Também tivemos que replicar toda a estrutura para manter a coerência entre as constraints das tabelas. Outro ponto que tivemos que repensar foi como seria feita a migração dos dados que estavam na tabela antiga. Se simplesmente fossem migrados todos os dados antes do microsserviço apontar para a nova tabela, o problema de downtime não seria resolvido, porque teríamos que parar o microsserviço, fazer a migração e depois colocar a nova versão que aponta para a nova tabela. Com isso chegamos à solução final, na qual decidimos realizar a migração de dados adicionando uma lógica no código para acessar os dados antigos e os novos. Abaixo a organização da implementação desta solução
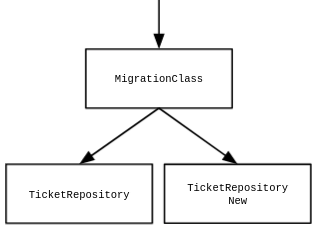
Portanto os novos registros eram salvos na tabela nova, e os registros na tabela antiga eram migrados à medida que os dados eram consultados. Para facilitar o entendimento, segue um snippet do código da classe (migrationClass) que contém as lógicas para inserção, consulta e atualização.
- Todos os registros novos, são inseridos na tabela novas.
public void add(Ticket ticket) {
ticketRepositoryNew.add(ticket);
}
- A consulta aos registros foi alterada. Além de ler os dados, também é realizada a migração dos registros para a tabela nova, caso eles se encontrem na tabela antiga. Depois de salvo na nova tabela, o registro é excluído da antiga.
public Ticket find(Integer id) {
try {
Ticket ticketOld = ticketRepository.find(id);
migrationTicket(ticketOld)
} catch (TicketNotFoundException e) {
logger.debug("Ticket not found in old table: {}", id);
}
return ticketRepositoryNew.find(id);
}
- A atualização de registros segue a lógica da consulta: caso o registro esteja na tabela antiga, primeiro ele é migrado para a tabela nova e depois sofre a atualização.
public void update(Ticket ticket) {
try {
Ticket ticketOld = ticketRepository.find(ticket.id());
migrationTicket(ticketOld)
} catch (TicketNotFoundException e) {
logger.debug("Ticket not found in old table: {}", id);
}
ticketRepositoryNew.save(ticket);
}
- Código da migração:
Private void migrationTicket(Ticket ticketOld) {
ticketRepositoryNew.insert(ticketOld);
ticketRepository.delete(ticketOld);
}
Com essa solução foi possível suportar UTF-8 na tabela, sem qualquer downtime no serviço. Os dados foram migrados aos poucos, sem sobrecarregar o sistema, uma vez que a migração só ocorre ao consultar/atualizar alguma informação. Os dados que permaneceram na tabela antiga, por não terem sido consultados/atualizados no período dedicado a migração automática, foram migrados manualmente após algum tempo, sendo finalizada a migração e possibilitando a remoção da tabela antiga e do código de migração.